Dentre as principais causas para o banco de dados tornar-se o gargalo do ambiente, a que geralmente se destaca é o aumento expressivo, ao longo do tempo, da quantidade de registros no banco de dados. Uma das consequências disso é que muito mais páginas de dados são lidas e alocadas em memória. No SQL Server todos os dados ficam armazenados em páginas de 8 KBs. Sempre que for necessário ler algum dado, que já não se encontra em memória, é efetuado um acesso ao disco para carregar as páginas necessárias. A partir de então, permanecem em memória para serem lidas durante um período, até que sejam desalocadas para novas páginas serem imputadas. Consultas que anteriormente executavam sem maiores problemas, agora podem virar o pesadelo de qualquer aplicação, principalmente quando existem desperdícios no banco de dados que poderiam ser evitados. Entre os principais fatores que acarretam em lentidão e instabilidade no servidor destacam-se: a ausência de índices assertivos, e/ou a forma que o código foi escrito.
Em relação a escrita do código existem certas “armadilhas” que são comuns de serem cometidas pelos desenvolvedores no seu dia a dia. Geralmente não são tão óbvias de serem detectadas mas são simples de serem ajustadas/evitadas.
select * from …
Existe uma piada interna no meio dos DBAs que sempre que um select * é utilizado em uma consulta um panda morre no mundo. E nunca é legal quando isso acontece.
Em um banco de dados, os dados da tabela se encontram no nodo folha (leaf) do índice clustered (tem um capítulo específico somente sobre índíces que esse e outros conceitos serão explicados no detalhe). Quando o código solicita todos os campos da tabela, obriga com que a engine do banco tenha que efetuar o acesso a esses dados através desse índice clustered. A essa operação dá-se o nome de KeyLookup e geralmente é uma operação custosa quando a quantidade de linhas retornada pela consulta é numerosa. Para minimizar esse processamento pode-se criar um índice coberto (covered) definindo na cláusula include alguns campos que serão utilizados com maior frequência nas consultas. Com isso não se faz necessário necessário recorrer ao índice clustered para recuperar esses dados. A pesquisa acontece apenas no índice coberto, que além de ser mais performático, pode minimizar inclusive a quantidade de bloqueios no banco de dados (locks). Porém, quando é utilizado o *, mesmo com a existência de um índice assertivo, ele pode ser ignorado pelo otimizador da consulta (Query Optimizer), devido justamente ao alto custo da operação de KeyLookup.
É preciso ter bom senso ao fazer uso da cláusula include em um índice com o intuito de criar um índice coberto. Não é incomum quando o desenvolvedor coloca todos os campos da tabela nessa cláusula, fazendo com que remédio dado ao paciente acabe por matá-lo. Isso gera um novo problema: a tabela acaba de ser duplicada na storage.
Também é preciso ter muito cuidado com o uso de ORMs na hora da codificação. É bem comum, por exemplo, utilizar o Entity Framework mapeando todos os campos da tabela em uma única classe e ao escrever uma consulta especificar a classe como um todo. Isso irá fazer com que todos os campos da tabela sejam retornados quando na verdade apenas alguns campos específicos geralmente são necessários. Para evitar cair nessa armadilha, o desenvolvedor deve fazer uso de projection, especificando somente os campos que realmente precisa.
 | Como desenvolvedor de código para banco de dados, a premissa principal sempre deve partir do seguinte “mantra”: Faça o máximo, com o mínimo possível. |
No exemplo a seguir é exemplificado esse comportamento. A tabela Person.Person do banco de dados AdventureWorks2019 tem o seguinte índice definido:
create nonclustered index IX_Person_EmailPromotion on [Person].[Person] ( EmailPromotion ) include ( ModifiedDate )
Quando é executado a seguinte consulta no banco de dados, o plano de execução (planos de execução e seus operadores também tem um capítulo exclusivo, na qual são tratados seus detalhes) resultante é o esperado:
select
BusinessEntityID,
EmailPromotion,
ModifiedDate
from [Person].[Person]
where EmailPromotion = 2
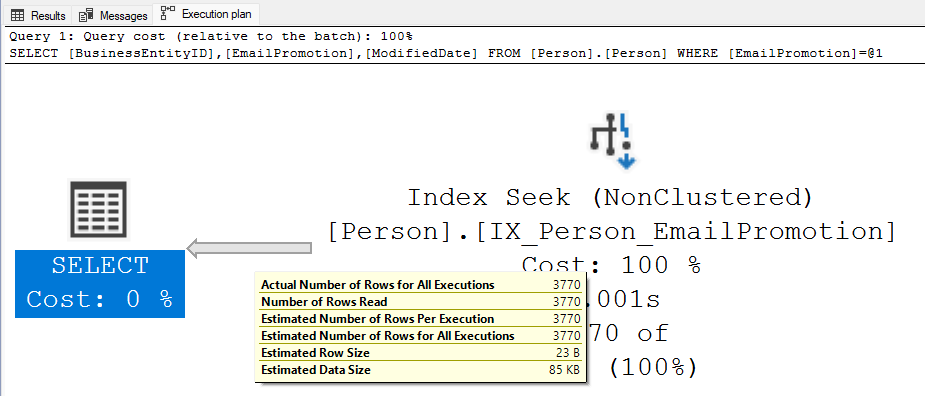
Para buscar os dados solicitados sequer foi necessário acessar diretamente a tabela Person.Person. O índice definido possui todos os dados quer foram solicitados pela consulta. Além disso, o método de busca foi um index seek, que é extremamente assertivo, visto que na consulta em questão foram lidos 3.770 (Number of Rows Read), e os mesmos 3.770 foram retornados (Actual Number of Rows for All executions).
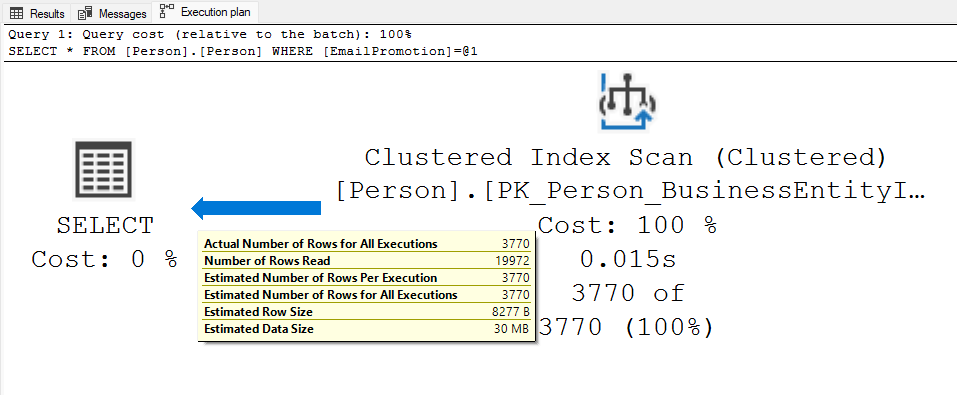
Quando a consulta é alterada para selecionar todos os campos da tabela, o plano de execução muda completamente. O motivo disso é o alto custo do operador de KeyLookUp para buscar os demais campos da tabela tendo para isso que acessar o índice clustered. O otimizador da consulta opta por efetuar um clustered index scan no PK_Person_BusinessEntityID, ao invés do index seek no índice IX_Person_EmailPromotion como vimos na consulta anterior. Quando isso acontece, acaba por percorrer toda a tabela, ou seja escanear os 19.972 registros, para selecionar os mesmos 3.700 registros, conforme mostrado abaixo:
select * from [Person].[Person] where EmailPromotion = 2
Poderia ser utilizado uma hint para forçar o uso de um índice específico, que é “esperado” ter uma melhor performance do que o scan na íntegra do índice clustered. Porém verifica-se que o Query Optimizer tomou a melhor decisão, ao optar pelo clustered index scan, visto que o custo dele é inferior ao custo utilizando-se a hint. Enquanto o plano de execução acima tem um custo de 1,75, o custo abaixo é de 6,46 (quase 4 vezes mais). Apenas a título de comparação, o custo da consulta especificando os campos, que faz uso do índice coberto, é de ínfimos 0,011?!?!
select
*
from [Person].[Person] with (index(IX_Person_EmailPromotion))
where EmailPromotion = 2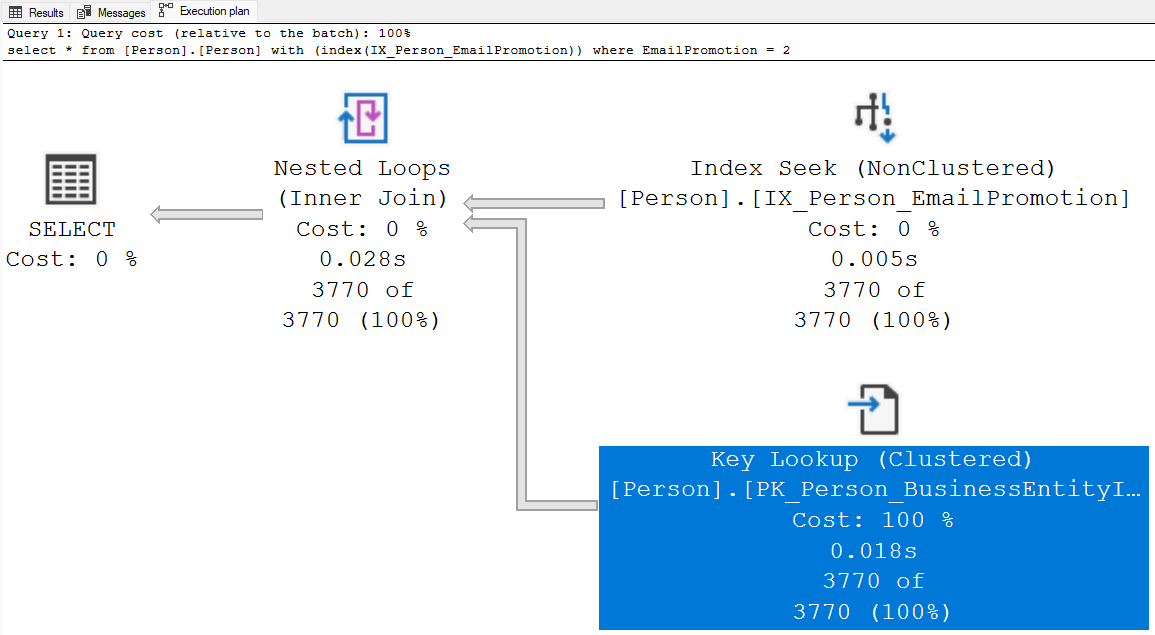
| Utilizar hints no código força com que o otimizador tome sempre a mesma decisão ao montar o plano de execução da consulta. Em alguns casos isso pode ser benéfico, mas é preciso fazer uso dessa funcionalidade com bastante cuidado. O banco de dados com o passar do tempo, tende a aumentar seu volume de dados, e uma consulta que performa bem hoje, pode não ter a mesma performance no futuro. Ao utilizar uma hint o desenvolvedor inviabiliza a capacidade do otimizador de se adaptar a essas mudanças de cenário. E na grande maioria das vezes o recomendado é deixar a cargo do otimizador essa decisão, pois geralmente (existem exceções) ele opta pelo melhor caminho quando se trata de performance. |
Conversões dos Tipos de Dados
Existem dois tipos de conversões dos tipos de dados no SQL Server: Explícita e Implícita.
A Explícita é quando é utilizado no código as funções de conversão de dados (convert ou cast) de forma proposital pelo desenvolvedor. Ex.: select convert(int, ’10’), select cast(’10’ as int)
A Implícita é quando a própria engine do banco de dados efetua a conversão de forma automática, de acordo com as regras de precedência do tipo de dados. Ex.: select nome from Clientes where codigo = ’10’ (sendo codigo do tipo inteiro)
Para ambos os casos de conversão, quando acontece dela estar sendo utilizada na cláusula where geralmente o resultado é trágico: Leitura na íntegra da tabela (table scan), mesmo nos casos que existem índices assertivos na tabela, ocorre o scan quando o esperado era um seek.
Devido a isso, é de extrema importância que essas conversões de dados sejam evitadas ao máximo, sempre respeitando o tipo definido na modelagem da tabela. Caso não seja possível, uma alternativa viável, por exemplo, para os casos em que ocorre uma integração de dados entre databases diferentes, com tipos de dados diferentes (Banco A usa varchar(50), Banco B uniqueidentifier, para armazenar o valor de determinado campo), pode ser utilizado colunas computadas ou Views indexadas para explicitamente efetuar a conversão, armazenando o dado em disco (de forma persistida) no tipo de dados que evita a conversão. Nesse caso irá ocorrer a redundância do dado para privilegiar a performance do banco, principalmente quando este campo participar de joins ou filtros (where).
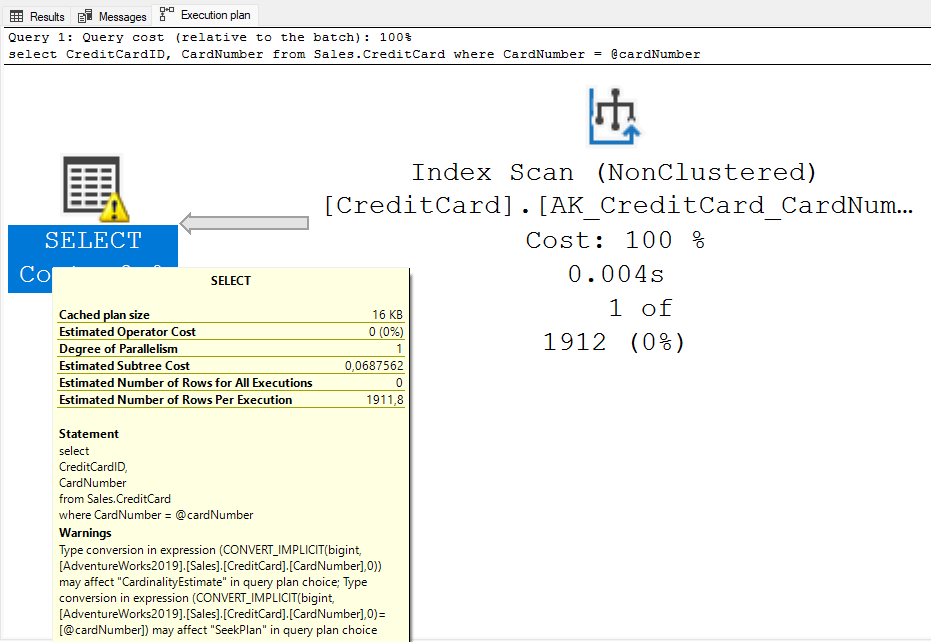
No exemplo abaixo o campo CardNumber da tabela Sales.CreditCard do banco AdventureWorks2019, é do tipo nvarchar(25). Entretanto está sendo consultado utilizando como parâmetro um número do tipo bigint. Isso irá gerar uma conversão implícita na hora de processar a consulta, que fará com que toda a tabela seja escaneada, conforme o plano de execução gerado mostra:
declare @cardNumber bigint = 11119775847802
select
CreditCardID,
CardNumber
from Sales.CreditCard
where CardNumber = @cardNumber
Quando é definido o tipo de dados correto, o otimizador consegue tomar uma decisão melhor, optando por utilizar o que seria o melhor índice para processar a consulta. Apenas olhando a largura das setas entre os operadores do plano de execução, é possível observar que muito menos dados foram lidos (1 de 1) em relação a consulta anterior, quando foi possível optar por utilizar o índice correto. Sempre coloque o N na frente de uma constante texto do tipo nvarchar, caso contrário será utilizado varchar, e isso também remete a uma conversão implícita.
declare @cardNumber nvarchar(25) = N'11119775847802'
select
CreditCardID,
CardNumber
from [Sales].[CreditCard]
where CardNumber = @cardNumber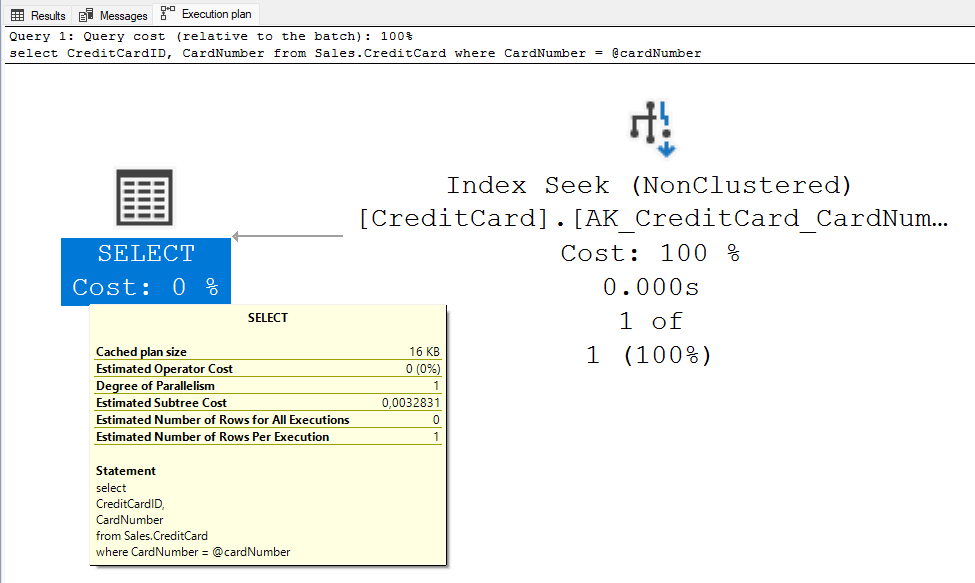
| É uma boa prática de codificação sempre definir o tipo do parâmetro quando utilizar linguagens de programação para escrever consultas ao banco de dados. Deixar a cargo da linguagem, pode ocasionar no uso de tipos de dados que causam conversões. Por exemplo em C#, quando um parâmetro do tipo texto (string) não é definido, por padrão é utilizado o nvarchar. Se por ventura, os campos das tabelas estejam definidos como varchar, pode ocorrer problemas de performance. |
Uso de Funções
Sempre que uma função estiver sendo utilizada na cláusula where sendo aplicada a algum campo da tabela, a engine do banco de dados necessita processar essa função em todas as linhas da tabela para poder identificar o valor resultante da expressão. Nesse caso, geralmente o tuning (ajuste na consulta para obter a melhor performance possível) aplicado é a reescrita do código para uma forma que não seja necessário o uso da função. Em casos que isso não seja possível, cria-se uma coluna computada persistida com o valor da expressão já resolvido. Geralmente é uma boa prática criar um índice para essa coluna, quando utilizada em buscas. Isso pode evitar o table scan na tabela fazendo com que a busca pelos registros seja muito mais performática.
Supondo o seguinte índice:
create nonclustered index IX_SalesOrderHeader_OrderDate on [Sales].[SalesOrderHeader] ( OrderDate )
Ao escrever uma consulta para trazer todos os registros do ano de 2011, no mês de outubro (10), que utiliza as funções year e month para atender o requisito, faz com que o índice seja escaneado, conforme demonstra o plano de execução abaixo:
select
SOH.SalesOrderID,
SOH.OrderDate
from Sales.SalesOrderHeader as SOH
where year(SOH.OrderDate) = 2011
and month(SOH.OrderDate) = 10
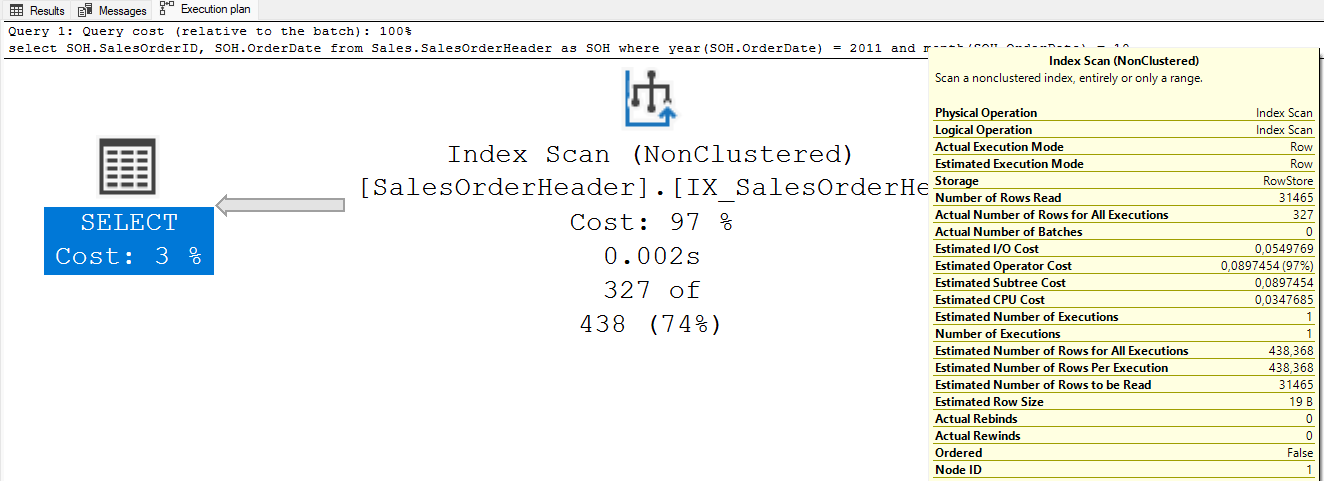
Na consulta acima, foi necessário ler 31.465 linhas para retornar 327 registros apenas. Para evitar esse desperdício de recursos na consulta, faz-se necessário reescrevê-la numa forma que evite o uso das funções acima:
select
SOH.SalesOrderID,
SOH.OrderDate
from Sales.SalesOrderHeader as SOH
where SOH.OrderDate between '20111001' and '20111031 23:59:59.997'
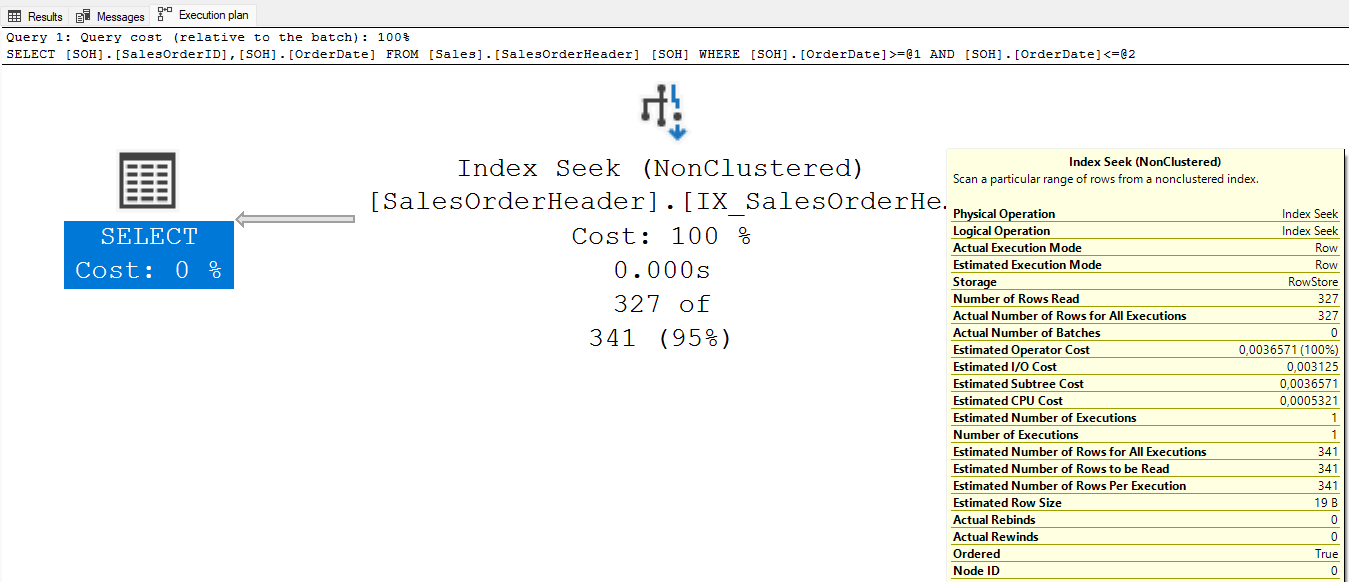
Agora foi possível usar o índice existente para ler somente os dados realmente necessários, efetuando um Index Seek ao invés do Scan. Somente 327 linhas foram lidas, ao invés das 31.465 linhas existentes na tabela.
| O formato das datas para o banco de dados é de acordo com a linguagem definida para o usuário no momento da sua criação. Uma forma de escrever consultas mais genéricas é utilizar as datas no formato YYYYMMDD HH:mm:ss.fff, que é um formato universal para o banco de dados. Desse jeito, ele sempre irá conseguir fazer a conversão de string para datetime sem maiores problemas. |
Alteração do Collation
É muito comum o desenvolvedor alterar o comportamento da aplicação, principalmente na busca por palavras, utilizando a cláusula collate nas consultas. O que num primeiro momento parece ser uma solução simples para resolver problemas tais como, não fazer distinção entre palavras com maiúsculas ou minúsculas (Case Insensitive), ou palavras sem e com acentos (Accent Insensitive), independente do que o usuário da aplicação tenha digitado para efetuar a busca, tem uma consequência ruim para o banco de dados. Como ele precisa aplicar a alteração do collation em todas as linhas da tabela antes de conseguir efetuar qualquer filtro ou busca, novamente a tabela inteira é lida na íntegra. O exemplo a seguir demonstra essa situação:
select
BusinessEntityID,
FirstName,
MiddleName,
LastName
from [Person].[Person]
where LastName collate Latin1_General_CI_AI like N'phillips%'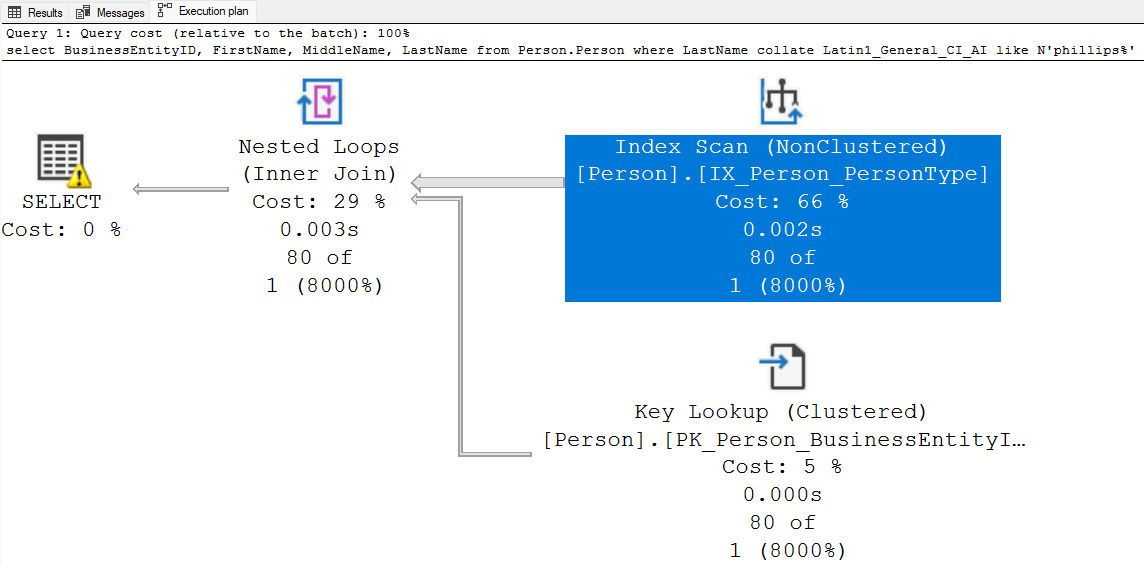
Nesses casos específicos de alteração no comportamento, adequar o collation da tabela ao requisito de negócio, pode ser a melhor solução em termos de performance. Essa é uma decisão que precisa ser planejada, pois para colocá-la em prática requer um certo trabalho, pois se faz necessário dropar todos os objetos que fazem acesso ao campo (índices, chaves estrangeiras, etc), alterar o collation do campo, e recriar os objetos novamente. Uma vez alterado o collation do campo, não é mais necessário o uso da cláusula collate, e a pesquisa faz o uso adequado do índice existente, efetuando um index seek no índice correto ao invés de scan no índice que o otimizador acha mais adequado (ele poderia ter optado pelo índice clustered também, na ausência de demais índices).
select
BusinessEntityID,
FirstName,
MiddleName,
LastName
from [Person].[Person]
where LastName like N'phillips%'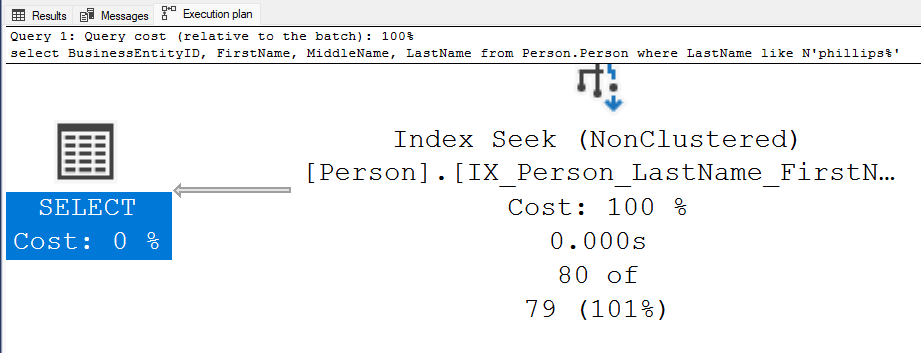
Um outro cenário comum em relação a collation é quando os databases de usuário estão com collations diferentes dos databases do sistema (Master, Model, TempDB). Ao utilizar-se de tabelas temporárias no código, na qual são feitos joins entre elas por campos texto (varchar, nvarchar, etc…) o desenvolvedor pode se deparar com um erro de conflito nos collations. Para evitar esse inconformidade, na hora da criação do database é importante que se utilize o mesmo collation dos databases do sistema. A troca do collation após a criação e uso do database não é uma tarefa trivial de ser feita, embora possível. Esta é uma decisão de design do banco de dados, que deveria ser definida no momento da instalação do servidor do banco de dados. Uma alternativa quando o database tem um collation diferente do TempDB é criar as tabelas temporárias com select … into #TabelaTemporaria, ao invés de create table #TabelaTemporaria. Isso garante que o collation de origem seja utilizado, ao invés do collation do TempDB, evitando assim o conflito.
| O operador like ‘%%’ sempre irá efetuar o scan da tabela na íntegra, independente do campo a ser buscado ter um índice ou não. Geralmente o servidor do banco de dados é instalado com o collation padrão que é o Latin1_General_CI_AS. Este é um collation do Windows. Uma vez que a leitura na íntegra da tabela não poderá será evitada, nesses casos seria interessante definir um collate do SQL, por exemplo SQL_Latin1_General_CP1_CI_AS. para ter ganhos de performance. Uma outra alternativa que pode ser viável é habilitar o uso de fulltext indexes, que são extremamente eficientes na busca por palavras. |
