É muito provável que todo desenvolvedor já codificou, em algum momento da sua jornada com programação, um aplicativo ou website que utiliza o conceito de Master-Detail em alguma parte da aplicação. Para quem não está familiarizado com este conceito, é quando existe uma lista (geralmente mostra-se os dados em formato de tabela) que apresenta alguns registros, e ao selecionar um registro em específico, é mostrado as informações detalhadas sobre ele. Até então, isso não deve ser novidade para ninguém, e em termos programáticos, não é uma dificuldade implementar algo nesse sentido.
Como minimizar o volume de dados retornados pela aplicação?
É em relação ao desenvolvimento do acesso aos dados onde geralmente os problemas acontecem. Quando existem tabelas com um volume muito grande de registros, se torna praticamente inviável para a aplicação carregar todos eles e retornar ao usuário final uma quantidade volumosa de dados. Não cometa esse erro. O usuário final sequer irá analisar todos os dados retornados caso o retorno da consulta ultrapasse 100 linhas. É muito provável que ele irá refazer a consulta refinando-a, utilizando algum critério a sua escolha para filtrar os resultados. Retornar uma quantidade massiva de dados provavelmente fará com que as consultas fiquem extremamente lentas, além de desperdiçar recursos valiosos do servidor do banco de dados (maior consumo de CPU e Memória, e em alguns casos, se faz necessário para o banco de dados efetuar um acesso ao disco para buscar informações que ainda não estão em memória), sem contar o tráfego de dados via rede entre o servidor do banco de dados e a aplicação. Provavelmente seja o prenúncio para problemas futuros.
Além da quantidade de registros retornados ser um problema, um outro erro cometido é trazer todas as informações necessárias para mostrar os dados tanto da Master (lista), quanto da Detail (formulário) em uma única requisição ao banco de dados. O problema dessa abordagem é que talvez o usuário final sequer clique em algum registro para carregar as informações detalhadas, mas o dado já foi previamente processado, embora talvez nunca venha a ser usado. A forma recomendada de implementar esse tipo de código, é selecionando o mínimo possível de informações (apenas para mostrar algumas colunas essenciais na grid) e sob demanda, quando realmente necessário, buscar as demais informações pertinentes em uma nova requisição ao banco de dados. Somente a partir de então, preenche-se o formulário dos detalhes. Nessa nova requisição, provavelmente seja utilizado como pesquisa o campo que está definindo como chave primária da tabela, que é a forma mais rápida de buscar algum registro em específico no banco de dados.
Uma das maneiras de solucionar o problema da quantidade de registros retornados em uma única consulta, é entregando a informação ao cliente de forma “particionada”, ou seja, utilizando o conceito de paginação dos dados. Com isso, ao invés de entregar um grande bloco de dados em uma única requisição, blocos menores serão retornados, e a medida que o usuário final solicitar mais informações, uma nova requisição ao banco de dados é efetuada e novos blocos menores de informação são novamente retornados.
No SQL Server, existem basicamente duas formas de implementar a paginação dos dados. Usando a window function ROW_NUMBER() (disponível a partir da versão 2005), e mais recentemente OFFSET… FETCH (disponível a partir da versão 2012). A seguir exemplos de uso para cada implementação, extraídos da documentação da própria Microsoft.
Usando row_number para limitar o número de linhas:
use AdventureWorks2019
go
;with cteOrders
as
(
select
SOH.SalesOrderID,
SOH.OrderDate,
row_number() over (order by SOH.OrderDate) as RowNumber
from Sales.SalesOrderHeader as SOH
)
select
SalesOrderID,
OrderDate,
RowNumber
from cteOrders
where RowNumber between 50 and 60
Reescrevendo a consulta acima, utilizando offset… fetch para limitar o mesmo conjunto de linhas:
use AdventureWorks2019
go
select
SOH.SalesOrderID,
SOH.OrderDate
from Sales.SalesOrderHeader as SOH
order by SOH.OrderDate
offset 49 rows
fetch next 10 rows only
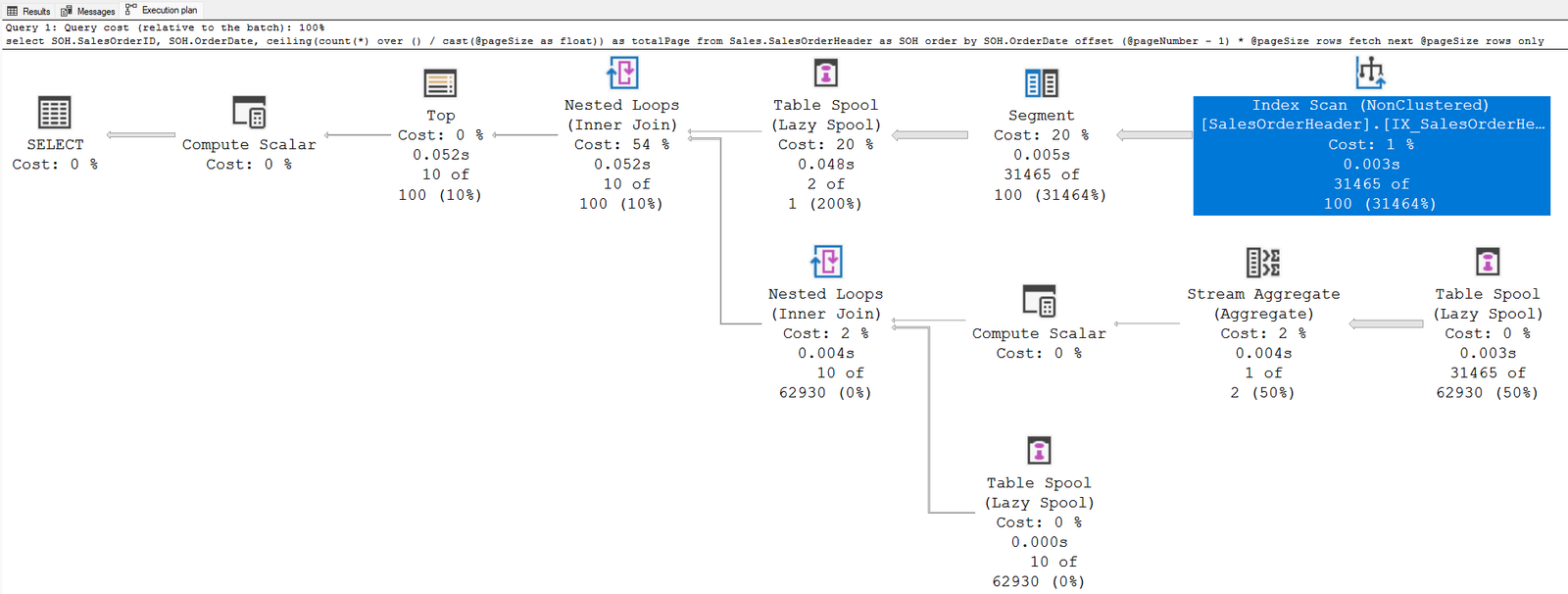
Particularmente utilizo o offset… fetch sempre que possível em detrimento ao row_number. Embora a sintaxe dele seja um pouco mais confusa, dessa forma, sua funcionalidade se assemelha ao TOP. A diferença principal é que não se faz necessário calcular o número para cada linha através da window function, que vem a ser um processamento a mais para o banco de dados, mesmo que irrisório. O plano de execução abaixo, mostra a diferenças entre os dois métodos. O custo adicional da primeira consulta, se justifica pela inclusão dos operadores Segment, Sequence Project, e Filter, necessários devido o uso do row_number. Na segunda consulta, foi utilizado um plano mais simples, com o mesmo resultado:

Implementar a paginação no formato “Página 1 de X” é uma prática bastante comum que afeta negativamente a performance, e que muitas vezes não se dá a devida relevância. O problema é que é necessário conhecer previamente quantas páginas no total a consulta retorna. O objetivo principal da paginação é justamente refinar a quantidade de registros que será necessário ler da tabela, para que não onere o banco de dados. Ao efetuar o levantamento total da quantidade de páginas, praticamente todo o resultado da consulta precisa ser lido. Não existe milagre a ser feito nesse caso. E isso pode ser desastroso quando a tabela já tem um volume considerável de dados. É muito provável que o usuário final, nunca venha a acessar as últimas páginas. Caso o número de páginas seja superior a 5, ele não vai sair clicando indefinidamente até não ter mais páginas para mostrar. Pesquise no Google uma palavra que tenha várias ocorrências. Acredito que você nunca tenha ido além da página 5 para buscar pela informação. Provavelmente tenha desistido e refinado sua pesquisa. Adeque sua aplicação a essa realidade.
Um “erro” que muitos cometem quando se trata de paginação de dados, é paginar no formato página 1 de X. Na qual é preciso conhecer quantas páginas no total a consulta retorna. O objetivo principal da paginação é justamente refinar a quantidade de registros que será necessário ler da tabela, para que não onere o banco de dados. Para efetuar o levantamento total da quantidade de páginas, praticamente todo o resultado da consulta precisa ser lido. Não existe milagre a ser feito nesse caso. E isso pode ser desastroso quando a tabela já tem um volume considerável de dados. É muito provável que o usuário final, nunca venha a acessar as últimas páginas. Caso o número de páginas seja superior a 4, ele não vai sair clicando infinitamente até não ter mais páginas para mostrar. Pesquise no Google uma palavra que tenha várias ocorrências. Acredito que você nunca tenha ido além da página 5 para buscar pela informação. Provavelmente tenha desistido e refinado sua pesquisa. Adeque sua aplicação a essa realidade.
Para atender a essa necessidade alguns fazem uso de tabela temporária, inserindo todos os registros nela, recuperando o @@rowcount para descobrir a quantidade de registros totais que foram inseridos, e após implementam a paginação na tabela temporária. Essa abordagem acaba por fazer uso excessivo do TempDB, o que nunca é recomendado. Fora que dependendo do caso, um volume de dados irá ser transferido entre ambos databases.
Outra forma é realizar duas vezes a consulta. Uma com o count sem utilizar a paginação, e outra utilizando-a. Também é uma abordagem ruim, pois nesse caso, foi praticamente executada a consulta em duplicidade.
A abordagem geralmente recomendada é utilizar uma window function para retornar a quantidade de páginas, como uma nova coluna, usando uma única consulta:
use AdventureWorks2019
go
declare
@pageNumber as int = 1,
@pageSize as int = 10
select
SOH.SalesOrderID,
SOH.OrderDate,
ceiling(count(*) over () / cast(@pageSize as float)) as totalPage
from Sales.SalesOrderHeader as SOH
order by SOH.OrderDate
offset (@pageNumber - 1) * @pageSize
rows fetch next @pageSize rows only
Presume-se que essa é a maneira menos onerosa de obter a informação do total de linhas. Mas não se engane, apesar de resolver o problema, foi necessário ler o resultado da consulta na totalidade, conforme mostra em destaque o Index Scan na tabela SalesOrderHeader. Nesse caso, todos os registros da tabela foram lidos. Deve-se utilizar essa abordagem apenas quando o número de linhas retornadas é conhecidamente pequeno. Fora isso, evite ao máximo implementar dessa forma.
Aplicando o conceito de paginação em um código da “vida real”, é interessante considerar o encapsulamento em uma stored procedure. Além disso, pode ser adicionado a flexibilidade do usuário escolher qual a ordem na qual os dados serão apresentados: CreationDate ou Score. Tanto de forma ascendente quanto descendente dos registros. Para isso será utilizado o banco de dados da StackOverflow. Nele existe uma tabela chamada Posts, que armazena cada questão feita no site por um determinado usuário, que é o proprietário do post (OwnerUserId). A tabela em questão tem cerca de 17 milhões de registros, e ocupa em torno de 37GBs do banco de dados.
Para este exercício, o banco de dados em questão, tem apenas as chaves primárias definidas. Seria inviável executar uma consulta que retornasse todos os registros dessa tabela para a aplicação, e por isso se torna obrigatório utilizar-se da paginação dos dados. Por questões de simplicidade, nenhum filtro (cláusula where) será empregado nos exemplos, porém é fundamental que eles sejam utilizados nas aplicações, com o intuito de refinar ao máximo as buscas.
Como a ordem da consulta é definida sob demanda pelo usuário final, é bastante comum, o desenvolvedor utilizar uma expressão case diretamente na consulta para montar dinamicamente a cláusula order by, da seguinte forma:
use StackOverflow2013
go
declare
@order int = 4,
@pageNumber as int = 1,
@pageSize as int = 10
select
P.Id,
P.Title,
P.CreationDate,
P.Score,
U.DisplayName,
U.Location
from dbo.Posts as P
inner join dbo.Users as U
on U.Id = P.OwnerUserId
order by
case when @order = 1 then P.CreationDate end asc,
case when @order = 2 then P.CreationDate end desc,
case when @order = 3 then P.Score end asc,
case when @order = 4 then P.Score end desc
offset (@pageNumber - 1) * @pageSize
rows fetch next @pageSize rows only

Codificar dessa maneira, causará um grande problema para o banco de dados pois, mesmo que existam índices específicos, eles serão ignorados, conforme mostrado no plano de execução acima, onde a tabela inteira foi escaneada.
A maneira adequada de escrever esse tipo de consulta é utilizar-se de Dynamic SQL conforme o código abaixo:
use StackOverflow2013
go
set ansi_nulls on
go
set quoted_identifier on
go
create or alter procedure dbo.usp_GetPosts
(
@order int = 1, -- ordem dos registros,
@pageNumber int = 1, -- número da página,
@pageSize int = 10 -- quantidade de registros retornados
)
as
begin
set nocount on
declare @orderBy varchar(50) =
case @order
when 2 then 'P.CreationDate desc'
when 3 then 'P.Score asc'
when 4 then 'P.Score desc'
else 'P.CreationDate asc'
end
declare @query as nvarchar(max) = convert(nvarchar(max), N'') + N'
select
P.Id,
P.Title,
P.CreationDate,
P.Score,
U.DisplayName,
U.Location
from dbo.[Posts] as P
inner join dbo.[Users] as U
on U.Id = P.OwnerUserId
order by ' + @orderBy + N'
offset (@pageNumber - 1) * @pageSize
rows fetch next @pageSize rows only'
exec sp_executesql
@stmt = @query,
@params = N'@pageNumber int, @pageSize int',
@pageNumber = @pageNumber,
@pageSize = @pageSize
end
goAo criar a stored procedure acima e após efetuar sua chamada, o seguinte plano de execução é utilizado:
exec usp_GetPosts 2, 10, 20
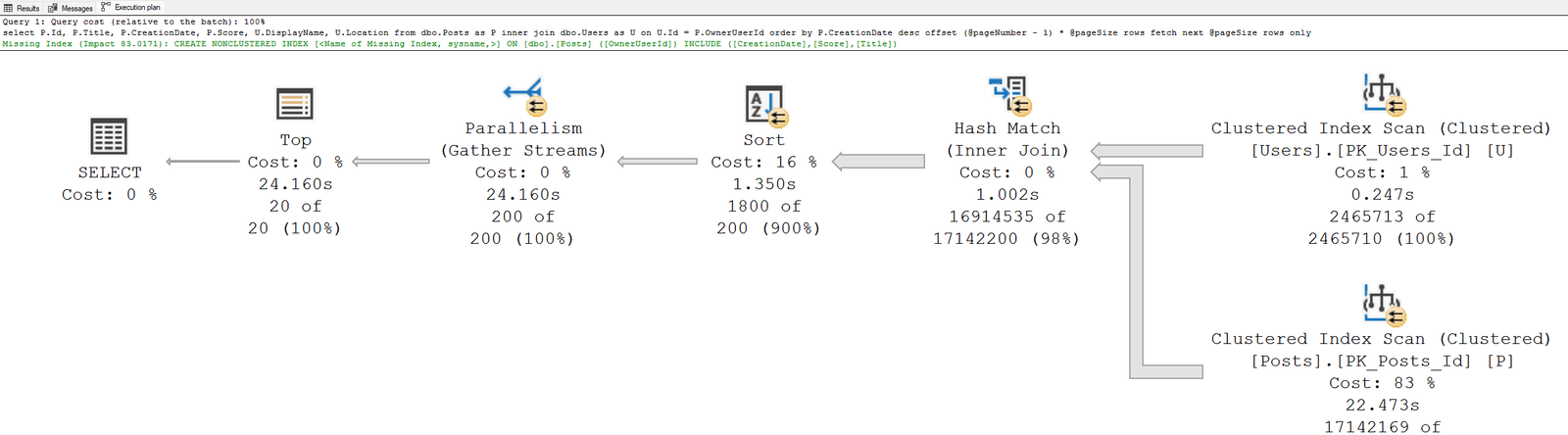
O plano de execução está longe de ser o ideal. O custo dele é de 3730(?!?!), o que é considerado altíssimo em termos de processamento. Como não existem índices (o que também pode ser observado na mensagem de missing index destacada em verde), foi necessário ler toda a tabela de Posts, e consequentemente a tabela de Users. Além disso, para conseguir processar mais rápido (demorou 25 segundos no meu ambiente) fez-se uso de paralelismo, acabando por utilizar as 12 CPUs disponíveis no servidor apenas para uma consulta. Para efetuar o tuning necessário neste caso, precisamos criar os índices adequados para a consulta em questão. O próprio SQL Server dá uma sugestão de índice que prevê um impacto positivo de 83,0171% no custo da consulta. Porém está longe de ser um índice assertivo neste caso, pois não irá trazer o benefício necessário para a consulta performar com excelência. Uma melhor solução é a criação dos dois índices cobertos abaixo, utilizando a cláusula include para os campos contidos no select:
create nonclustered index IX_Posts_CreationDate
on dbo.[Posts]
(
CreationDate
)
include
(
Title,
Score,
OwnerUserID
)
create nonclustered index IX_Posts_Score
on dbo.[Posts]
(
Score
)
include
(
Title,
CreationDate,
OwnerUserID
)
Após a criação dos índices, o plano de execução quando a stored procedure é executada, agora está próximo do ideal, independente da ordem escolhida pelo usuário. O custo da consulta caiu para ínfimos 0.66 e foi utilizado apenas uma única CPU para seu processamento.
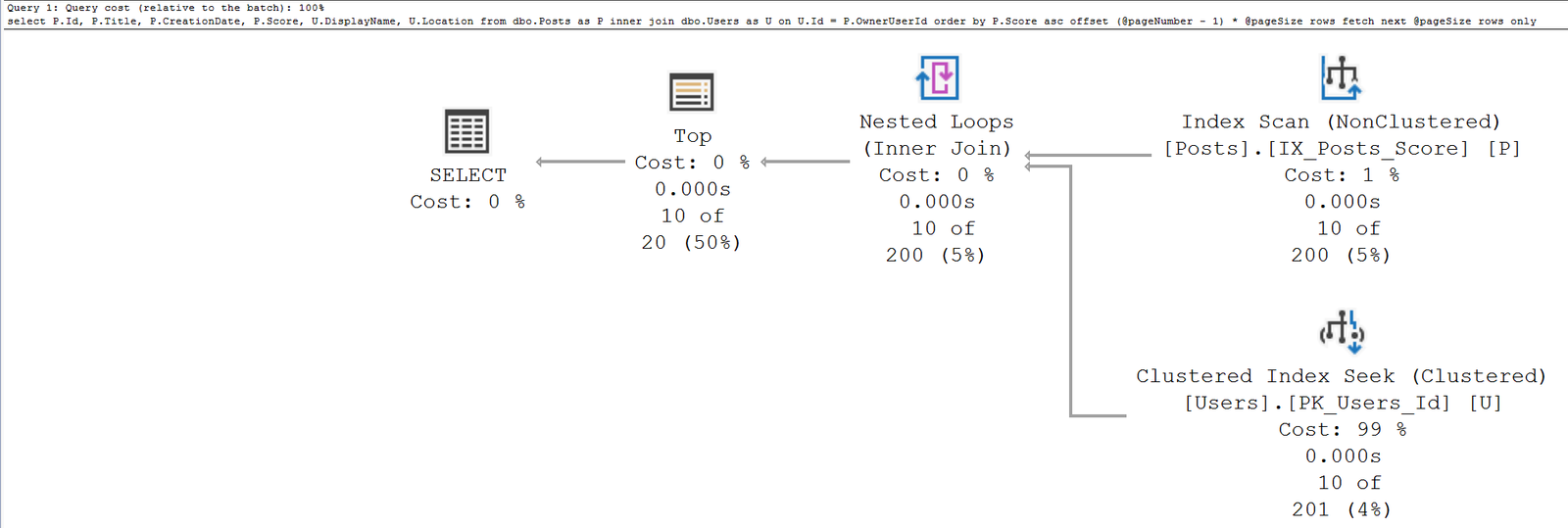
 Quando uma consulta possuir as cláusulas order by e top/offset, na ausência da cláusula where é bem provável que os campos definidos na cláusula order by sejam possíveis candidatos para tornarem-se índices. Geralmente passam a ser o melhor fator de restritividade de registros da tabela.
Quando uma consulta possuir as cláusulas order by e top/offset, na ausência da cláusula where é bem provável que os campos definidos na cláusula order by sejam possíveis candidatos para tornarem-se índices. Geralmente passam a ser o melhor fator de restritividade de registros da tabela.
Indo além na solução do problema
Na grande maioria dos cenários, após implementado o tuning acima, que aparentemente resolveu o problema de forma pontual (o custo caiu de 3730 para 0.66 usando um único processador), a solução se mostra satisfatória. Talvez essa consulta sequer entraria no radar como problemática do jeito que está implementada. Porém, ainda existe um desperdício que pode ser evitado. A redundância tripla nos campos CreationDate, Score, Title e OwnerUserID. Além de existirem na tabela, agora também estão nos dois índices criados para resolver o problema de performance. Para isso foi penalizado a storage do servidor. Obviamente no exemplo acima, são poucos campos sendo retornados, mas no nosso dia a dia, não é sempre assim que acontece. Quanto mais campos forem utilizados na cláusula include do índice, maior o tamanho necessário para armazenamento em disco. Obviamente, dentre os três principais recursos (CPU, Memória e Disco), os dois primeiros são mais caros e limitados que o terceiro, sendo assim a escolha por qual recurso é preferível de ser penalizado é tranquila, de certa forma, de ser feita. Mas e se existisse uma maneira de resolver o problema da paginação dos dados, sem essas penalizações ao ambiente?
Por motivos de comparação vamos criar uma nova versão da stored procedure usp_GetPosts, reescrevendo-a da seguinte forma:
use StackOverflow2013
go
set ansi_nulls on
go
set quoted_identifier on
go
create or alter procedure dbo.usp_GetPosts2
(
@order int = 1, -- ordem dos registros,
@pageNumber int = 1, -- número da página,
@pageSize int = 10 -- quantidade de registros retornados
)
as
begin
set nocount on
declare @orderBy varchar(50) =
case @order
when 2 then 'P.CreationDate desc'
when 3 then 'P.Score asc'
when 4 then 'P.Score desc'
else 'P.CreationDate asc'
end
declare @query as nvarchar(max) = convert(nvarchar(max), N'') + N'
;with ctePosts
as
(
select
P.Id
from dbo.[Posts] as P
order by ' + @orderBy + N'
offset (@pageNumber - 1) * @pageSize
rows fetch next @pageSize rows only
)
select
P.Id,
P.Title,
P.CreationDate,
P.Score,
U.DisplayName,
U.Location
from ctePosts as C
inner join dbo.[Posts] as P
on P.Id = C.Id
inner join dbo.[Users] as U
on U.Id = P.OwnerUserId'
exec sp_executesql
@stmt = @query,
@params = N'@pageNumber int, @pageSize int',
@pageNumber = @pageNumber,
@pageSize = @pageSize
end
go
Também será criado uma nova versão dos índices necessários para a consulta, porém sem fazer uso da cláusula include, o que irá diminuir o tamanho dos índices (logo mais eficiência em relação a busca e uso de memória, uma vez que isso acaba por diminuir também a quantidade de páginas de dados):
create nonclustered index IX_Posts_CreationDate2
on dbo.[Posts]
(
CreationDate
)
create nonclustered index IX_Posts_Score2
on dbo.[Posts]
(
Score
)
Comparando o plano de execução de ambos códigos, nota-se que houve um ganho em relação ao custo da consulta:
exec usp_GetPosts 2, 10, 20 exec usp_GetPosts2 2, 10, 20
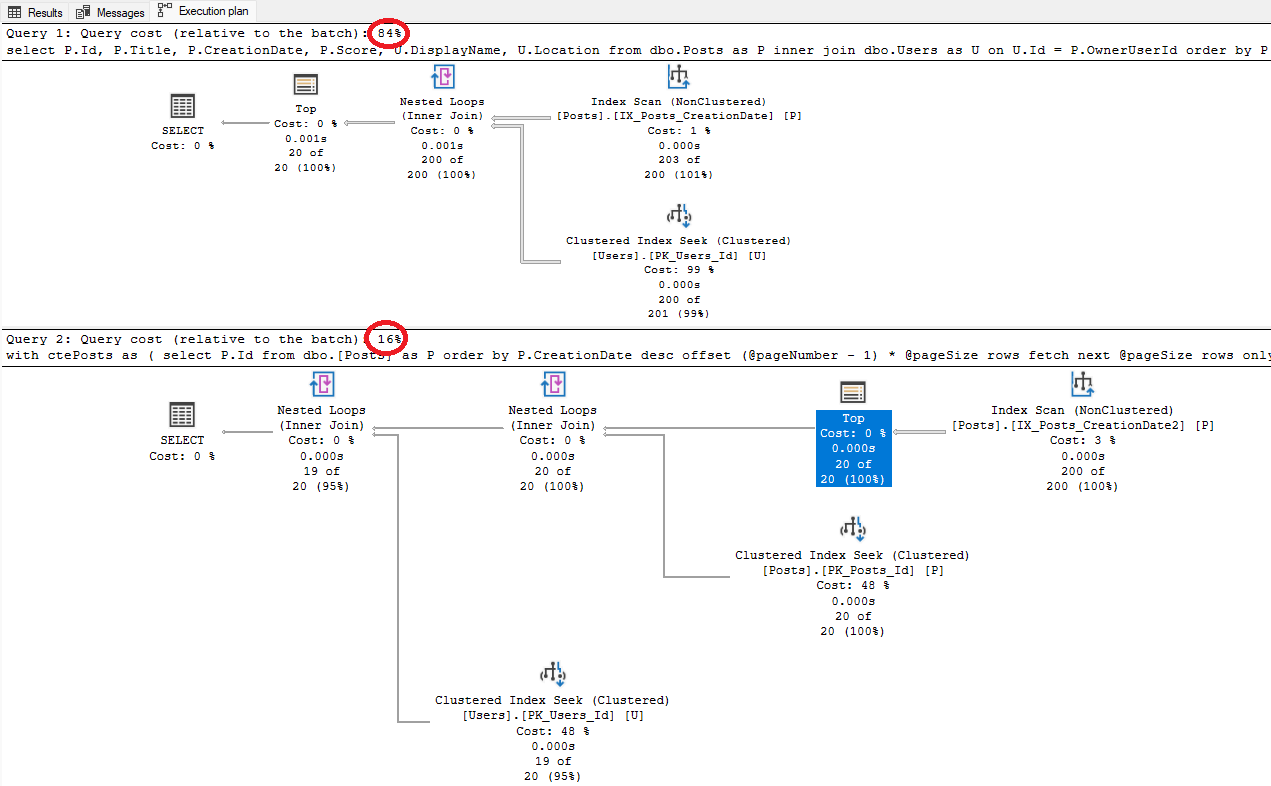
Nessa nova versão do código, o custo da consulta caiu para 0.12. Basicamente foi implementado manualmente o operador de KeyLookUp, uma vez que serão selecionados os registros a serem paginados e após será efetuado um clustered index seek de cada um dos registros (a quantidade de seeks será de acordo com o valor informado para o parâmetro @pageSize). É importante salientar que o operador Top, como mostrado na imagem acima, é “adiantando” no plano de execução. O benefício disso é que na hora de efetuar o join com a tabela de Users, os registros já foram previamente filtrados.
Em relação ao tamanho dos índices e página de dados, é possível visualizar a economia substancial causada ao ambiente na imagem abaixo, mais de 1.5 GBs e em torno de 200k de páginas de dados a menos. Poderia ainda ser utilizado um algoritmo de compactação nos índices e ter um ganho ainda mais substancial na storage. Mas isso é assunto para um outro artigo.

O uso do código escrito da forma correta para disponibilizar as informações aos usuários da aplicação, faz total diferença para o banco de dados. Por ser um dos recursos na TI que tem um custo elevado, dificuldade quanto a escalabilidade, além de outras limitações computacionais para a carga de trabalho que é demandada, se faz necessário atentar para cada mínimo detalhe na hora da implementação do acesso aos dados.
Nos dias atuais, em que é cada vez mais é considerado normal um grande volume de dados gerados pelas aplicações, qualquer dos recursos que seja acidentalmente desperdiçado, faz total diferença para a estabilidade do servidor do banco de dados, consequentemente para a aplicação. Utilizar a paginação de dados para retornar as informações para o usuário final “em parcelas”, pode ser uma saída eficaz para contornar essas limitações, sem onerar o ambiente.
